Automated Software Release Versioning in Gitlab CI
Short summary
In this blog post, we discuss software version control systems, their benefits, and the challenges associated with them. We also explain the benefits of automating software versioning and the need for creating additional unique identifiers that carry relevant information. We also talk about our experience in using Git and Gitlab and our decision to create an in-house solution for version control and the reasoning behind it and conclude with instructions for the steps involved in setting up and using our versioning automation.
The code for the Gitlab CI versioning job is available here: base58-public/ci/templates/Auto-Versioning.yml
The state of software versioning and the challenges associated with it.
Software version control systems are needed to keep track of software changes over time. Modern version control systems allow developers not only to easily identify which version of the software is currently in use but also to "surf" versions and branches to isolate or roll back segments of code when needed. This makes it possible to integrate and test new code segments integrated into projects in isolated environments before applying the changes to branches used by collaborators. Version control systems make it possible to test out solutions without fear of breaking things and even to deliver different versions of the project to different customers.
While multiple version control systems have been in wide use since the early days of computing, the creation of Git in 2005 has enabled software development as we know it today. As far as age-old legends go, compared to the last champion of version control - Subversion (SVN), Git had better branching and merging capabilities, it could be used as fully decentralized and had a larger level of support for non-linear development, which made it easier to manage large projects. Git also has a staging area that allows developers to easily review and commit changes to the repository.
Version control systems are extremely powerful tools but collaboration and complex work demand a certain level of organization within a team, so strict workflows are usually designed and implemented to keep projects from becoming mind-boggling messes. These workflows include branching models e.g. "Git Flow'' and systems for assigning custom version tags to software. Some of the popular systems for assigning version numbers to software releases are:
Semantic Versioning or SemVer
Semantic Versioning is a popular versioning system that uses a three-part version number - MAJOR.MINOR.PATCH - to indicate changes in the software. The MAJOR version is incremented when there are incompatible API changes, the MINOR version is incremented when there are new features, and the PATCH version is incremented when there are bug fixes.
e.g 1.0.0, 1.0.1, 1.1.0, 1.1.0-alpha, etc.
Calendar Versioning
Calendar Versioning is a versioning system that uses a date-based version number - YYYY.MM.DD - to indicate changes in the software. The YYYY part is incremented when there are incompatible API changes, the MM part is incremented when there are new features, and the DD part is incremented when there are bug fixes.
E.g. 2020.1, 2020.2, 2020.3, etc.
Sequential Versioning
Sequential Versioning is a versioning system that uses a simple incrementing version number - X.Y.Z - to indicate changes in the software. The X part is incremented when there are incompatible API changes, the Y part is incremented when there are new features, and the Z part is incremented when there are bug fixes.
E.g. 1.0, 1.1, 1.2, 1.3, etc.
Apache Maven versioning system
The Apache Maven versioning system is an implementation of the Semantic Versioning concept.
The main difference between the two systems is that Apache Maven uses an incremental version number, while semantic versioning uses a patch version number. This means that Apache Maven will increment the version number for every change, while semantic versioning will only increment the version number when there are bug fixes or MINOR changes. It also uses a qualifier as the last part of the version tag. The qualifier can be either RELEASE, SNAPSHOT, RC (for Release Candidate) or "M" (for Milestone), or a specific version identifier.
E.g. 1.1.0-RELEASE, 1.1.0-SNAPSHOT … 1.1.20-SNAPSHOT etc.
Our reasoning
Even with all tools and workflows in place a lot of repetitive tasks need to be done during the life cycles of projects. Our idea was to minimize the room for human error and maximize developers' uninterrupted time working on the actual tasks and features, as well as to open up more time for the automation of other processes. ( we are always striving for the automation of repetitive work processes). Although everything is indeed automatically versioned by default in Git with SHA-1 hash checksums (it is a modern Version Control system after all), the unique identifiers that are assigned automatically do not necessarily carry all the information that we need. The unique commit identifiers for every commit can be used to track down what piece of code was run or included, and the time and location from where the version came, but this process needs more engagement than a simple mental calculation. To have an Idea of what you got from software tagged with the unique commit identifier you would first need to have access to the project repository and then track down the identifier in the commits to determine the relative placement of the commit, the branch, and what is included in the commit. By looking at a list of unique commit identifiers you can not get any information about the order they were created in. The solution to this problem is to create additional unique identifiers that carry some relevant information, which is the best case for both human and machine readability. The data that ideally needs to be included in a unique version identifier is as follows:
- Version identity - QA and Developers need to know how to communicate the exact version used, what version had reproducible bugs, and what versions include fixes or new features.
- The intended users and environments for the software - anything on develop is intended for early testing and test environments, and anything on master/main is intended for staging and production environments.
- The order of commits needs to always be readable and incremental.
- The type of the commit needs to be readable so supplements and enforced information are needed for integration or deployments - Is the version newer than the one deployed, is it a breaking change in the API, etc.
As users of the Java ecosystem and to be able to easily integrate the publishing of packages with the Maven package repositories we decided to use an Apache Maven versioning system implementation that would adhere to both Apache Maven versioning system guidelines and our branching model, but at first, we implemented it manually.
We grew accustomed to a streamlined git-flow spin-off as our workflow and decided to use mainly feature, develop, and master/main branches. We are making sure that all code on develop is stable and tested before releasing directly to the master/main branch that corresponds to production-ready software. In this model we needed to make sure that software on the develop branch is golden before merging it to main/master, so most of the testing is based on the develop branch and as we are working mainly with multi-repo layouts it is important to get versioning of QA/dev environments just right.
As we decided to make our software version number assignment as automated as possible, it made sense to start versioning every commit that gets on the develop branch and then to "iterate up" the release version on the main branch with
MAJOR.MINOR.HOTFIX-RELEASE and MAJOR.MINOR.INCREMENT-SNAPSHOT formats.
Although some open-source software versioning automation tools exist, we created our own solution that would adhere to our project development and branching model out of the box.
As we used both Git and Gitlab we decided to use the inbuilt mechanisms to create a solution.
GitLab CI uses bash in the CI's script component so we proceeded to use that. Git has a label feature that is also integrated with Gitlab merge requests.
We decided to use the above-mentioned features as they offered us both a point in time when we decide what version place we will increment and a way to read the version state through the GitLab API.
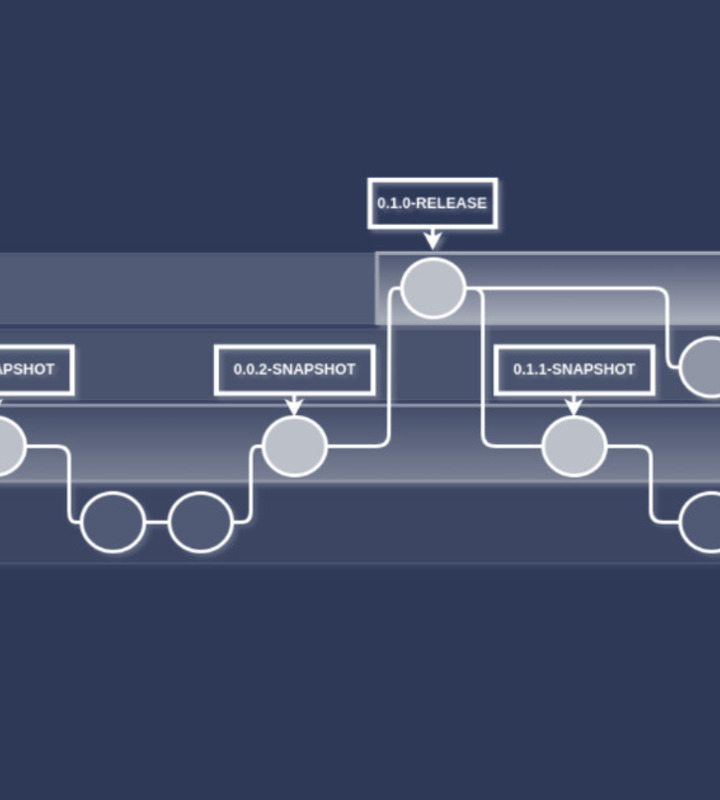
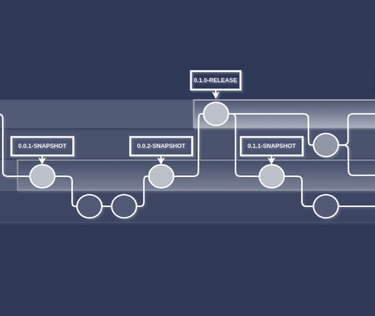
Our git workflow:

Our solution
- Only branches that we version are develop and master/main
- All CI build products on the mentioned branches are versioned, this includes jar files, frontend archives, and docker images.
- Snapshots are CI auto-incremented versions given to commits on develop branch
- Releases are CI auto-incremented versions given to commits on the master/main branch
- formats are MAJOR.MINOR.HOTFIX-RELEASE and MAJOR.MINOR.INCREMENT-SNAPSHOT
The versioning process could be broken up into the following steps:
- Getting the version type label - A label needs to be added to the merge request, it will be used to determine the position of the version incrementation. The options are increment::major increment::minor, increment::hotfix or increment::none
An undefined label will result in automatically incrementing the MINOR position in the given MAJOR.MINOR.HOTFIX format.
- Setting the label to none will skip the version incrementation
- Cloning the git project and checking out the commit branch that the CI job runs on for git-tag manipulation purposes
- Determining the previous version
- Defining the regex increment recipes
- Determining if the previous version, version type, and origin
- Determining the type of the new version
- Using the git tag command with the modified version tag
- Pushing the new tag to the remote repository
After the steps above, the commit contains a git tag with the new version.
Now the version can be integrated with the build process and the software is tagged with the appropriate version.
Integration examples
After the versioning script is done you can introduce the version in any project job for further use by defining it with
VERSION=$(git tag --points-at $CI_COMMIT_SHORT_SHA)
Then you can use it with little effort in any build job. Here are some examples:
For Docker integration add a label to the Dockerfile:
ARG VERSION
LABEL project_version="${VERSION}"
And later you can check the label by using:
docker image inspect <DOCKER_IMAGE> |grep project_version
For Java Gradle Integration make sure that version is not defined in build.gradle and that a line like this one does not exist: version = 'some_version' And in the CI build job, before the gradle build export the ORG_GRADLE_PROJECT_version variable:
export ORG_GRADLE_PROJECT_version=$(git tag |grep -e SNAPSHOT | sort -V | tail -n1)
For React integration introduce the version on npm run build step
npm run build REACT_APP_BASE_URL=$REACT_APP_BASE_URL REACT_APP_VERSION=$VERSION
and you can then call the variable in the code with
process.env.REACT_APP_VERSION
Process behaviour
Default behaviour - Versioning Merges and commits, without specifying any labels:

New commits after release to both develop and hotfix and merge of hotfix branch commit to master/main and develop:

New commits after release to hotfix and merge of hotfix branch commit to master/main and develop:

Conclusion
All in all, we are satisfied with the outcome:
- Communication between QA and DEV departments has become more concise as versions are used in Jira tickets to define software versions where issues can be reproduced.
- 99% of the time we let the automation do the work, with no need to interfere. We treat the version tags designated by our automation as unique and only iterate up, keeping the version tag history solid and intact. We version up even if we just need to change one small line of code on the master/main or the develop branch. Manual intervention is necessary when working on new MAJOR or HOTFIX versions, as everything else is considered a MINOR version bump (MAJOR.MINOR.HOTFIX) on the master/main branch, and version bumps are always treated as incremental (MAJOR.MINOR.INCREMENTAL) on the develop branch.
- There are also less things that can go wrong and need to be checked during releases.
If you want to know more about automated software release versioning, let's talk at contact@base58.hr.
"If I had to do it all over again, I wouldn't change a thing" - Unknown



